Activation Function



Activation functions play a crucial role in Artificial Neural Networks as they determine the nature of the output in each layer of our model. Using the wrong kind of activation function can hinder our training and lead to awful models. In this post, we are going to discuss some of the common activation functions.
Sigmoid Activation Function
Sigmoid function is one of the most commonly used activation function in neural network, especially when the output had be between 0 to 1, like in case of probabilities. The value for given x is calculated using the function mentioned below:
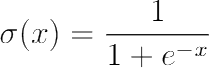
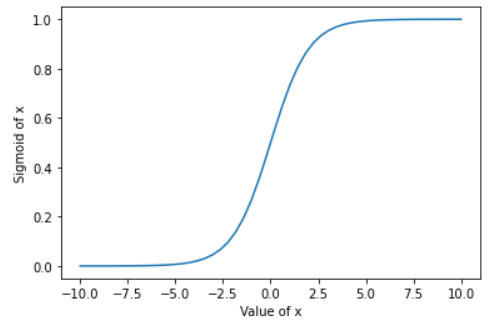
One of the major drawbacks of using sigmoid activation function is that for very high or low values of X, the change in prediction is insignificant which may lead to vanishing gradient problem as the derivative of sigmoid function will be very close to zero.
Implementation of sigmoid function using Numpy:
def sigmoid(X):
Y = 1/(1+np.exp(-X))
return Y
Tanh Activation Function
Tanh or hyperbolic tangent function is similar to sigmoid function however it is zero centered, assigning -1 for strongly negative inputs and +1 for strongly positive inputs. Neutral values are mapped near zero in tanh graph. The value for given x is calculated using the function mentioned below:
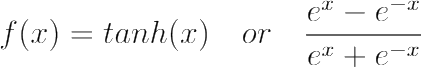
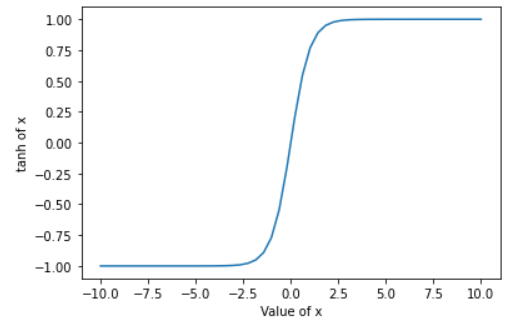
Like in sigmoid activation function, very high or low values of X, the change in prediction is very small which leads to vanishing gradient problem as the derivative of tanh function will be tends to zero.
Implementation of Tanh function using Numpy:
def tanh(X):
Y = np.tanh(X)
return Y
ReLU Activation Function
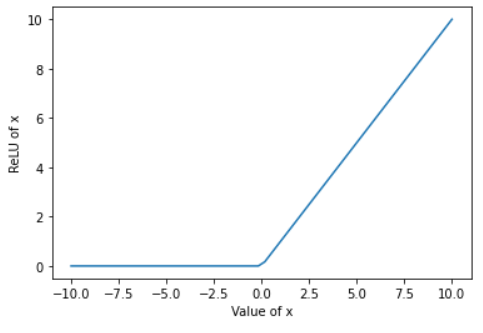
ReLU or Rectified Linear Unit is a non-linear activation function with range [0-∞]. The value for given x is calculated using the function mentioned below:
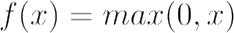
Unlike tanh or sigmoid, derivative of high values of X is not zero. However ReLU has its own drawbacks, called Dying ReLU Problem. Dying ReLU Problem refers to the situation where input approaches zero or is negative then the derivative becomes zero, thus making back propagation not possible.
Implementation of ReLU function using Numpy:
def ReLU(X):
Y = X*(X>0) #All elements greater than 0 will retain the value whereas rest will be 0
return Y
Leaky ReLU Activation Function
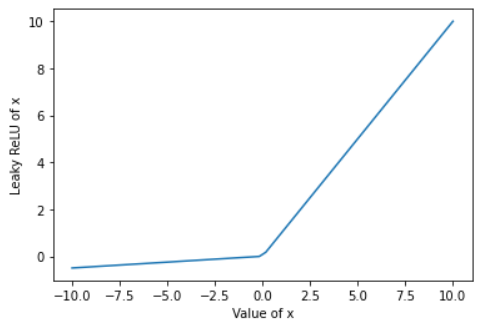
Leaky ReLU is a non-linear activation function similar to ReLU however it does not give zero as output for negative inputs. Rather it has a small slope for negative values thus making back propagation is possible. The value for given x is calculated using the function mentioned below, note that 0.01 is the slope of negative values and can be replaced by suitable small value:
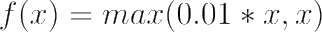
Leaky ReLU solves the Dying ReLU Problem as negative inputs do not have zero as derivative, however, it does not provide consistent prediction for negative values as the slope for negative inputs is a constant.
Implementation of Leaky ReLU function using Numpy:
def LReLU(X,slope=0.01):
Y1 = X*(X>0) #For elements greater than 0
Y2 = slope*X*(X<=0) #for elements less than or equal to 0
Y = Y1+Y2
return Y
Softmax Activation Function
Softmax function is generally used in architecture where we classify the input into a particular category. In such scenarios, we need a winner-takes-all approach where the numbers are converted to probability with the predicted category having a high value (approaching 1 if absolutely certain), while those which are eliminated have probabilities near zero. The value for any element i in vector x of length K can be calculated using the function mentioned below:
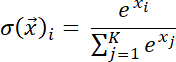
Implementation of Softmax function using Numpy:
def softmax(X):
EXP = np.exp(X)
Y = np.exp(X)/sum(EXP)
return Y
In this post we have discussed some of the common activation functions and their basic features. While most modern libraries like Pytorch, Tensorflow and Keras provide these activation function it is important to understand their working. You can find the code for this blogpost in this github repo. Do refer to this graph for a detailed visualization of various activation functions.